

This is the fourth and final installment in our series about bringing AI to Bitrise. In Part 1, we explained why we built our own AI coding agent. Part 2 covered our browser-integrated AI Assistant. Part 3 detailed how we brought AI to the Bitrise Build Hub. In this final post, we'll explore how we unified these efforts into a cohesive AI Platform.
The challenge of scaling AI across an organization
As we shipped more AI features, a familiar pattern emerged: multiple teams across Bitrise started building their own AI-powered capabilities. PR review, failed build summaries, cache invocation summaries: each team was solving similar problems independently. We were duplicating effort and inconsistently handling LLM interactions, and we lacked visibility into how our AI features performed in production.
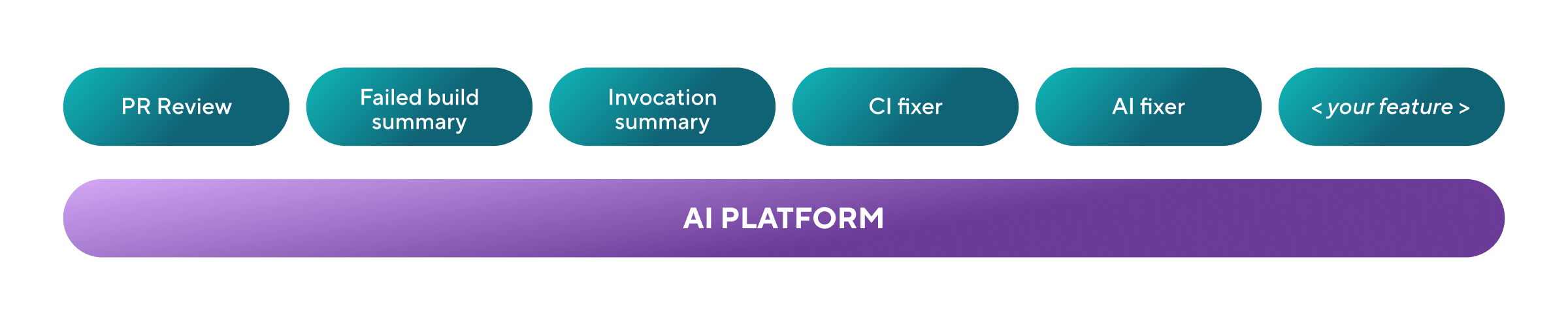
We needed to share common functionalities, libraries, and best practices across teams. The solution was building an internal AI Platform: a set of building blocks that any team could use to ship production-ready AI features.
The north star architecture
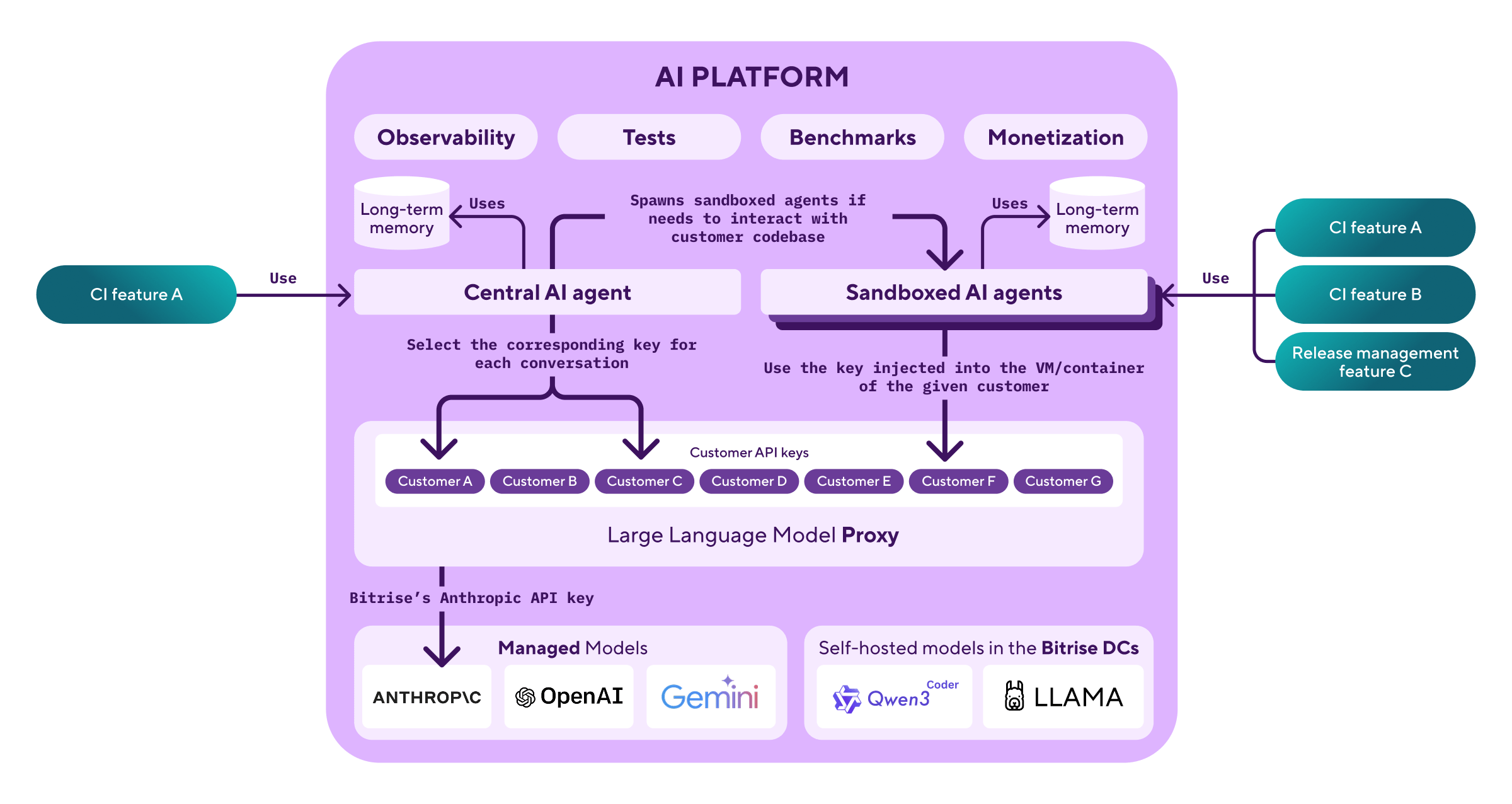
Our AI Platform provides common building blocks for implementing customer-facing, production-ready AI features. At its core, it includes:
- Feature-agnostic observability for agent statistics, token usage, and error tracking.
- A test and benchmarking framework to measure agent performance from isolated unit tests to real-world E2E tests.
- A golden path for monetization so teams can predictably price and bill for AI features.
When customer-facing teams implement AI features using these building blocks, we ensure that:
- all features use approved LLM providers and models;
- we can migrate all features centrally from one provider to another; and,
- we have consistent observability and monetization architecture across the board.
Large language models: the foundation
LLMs are the lowest-level building block in our platform. We use managed models hosted by providers like OpenAI, Anthropic, and Google, connecting to their API endpoints and paying based on usage.
While offering a "bring-your-own API key" setup is an option, we have chosen to fully integrate this layer into our product for several strategic reasons:
- Optimal customer experience: by controlling the AI models used, we can fine-tune and optimize our AI features to deliver the best possible experience to our customers.
- Predictable pricing model: instead of variable costs based on token usage ($X per used token), we offer predictable, feature-based pricing. This is achieved by calculating the average cost of an AI feature and then providing a fixed volume, such as "500 AI-based PR reviews/month," within a specific Bitrise plan.
We also have options for self-hosting open-source models in Bitrise data centers. This requires GPU hardware but offers a one-time cost independent of usage, and critically, keeps customer data within Bitrise systems.
Currently, we primarily use Anthropic because (at time of writing) they offer the best coding agent-related models. Our partnership with Anthropic allows us to lift rate limits and get assistance with issues when needed. (See the first post in this series for more.)
The LLM proxy: why we built our own
AI agents don't directly interact with LLM APIs in our architecture, for two key reasons:
- Most providers lack the capability to independently measure and bill customers at the LLM layer. Agent-reported data is susceptible to tampering.
- Even if a provider offers such an API, we may switch providers, and we don’t want to have to reimplement all dependent functionalities.
We added an LLM proxy between the LLMs and AI agents. This solves both problems by providing an adequate administrative API. We create "virtual" LLM API keys for our customers, passing them to their AI agents. We maintain a single LLM API key at the configured provider and proxy traffic between the two, measuring and budgeting per customer key.
We considered using off-the-shelf solutions like LiteLLM (as we’ve been using it for small internal workloads), but ultimately we didn't find any stable, performant solution that could handle our production traffic. In the end, we chose to implement a more minimalistic but high-performing, production-ready proxy for customer workloads.
Our proxy supports the Anthropic LLM API for incoming and outgoing traffic. It creates virtual keys, counts token usage, enforces budgets, and reports to our metric collectors.
Two types of AI agents
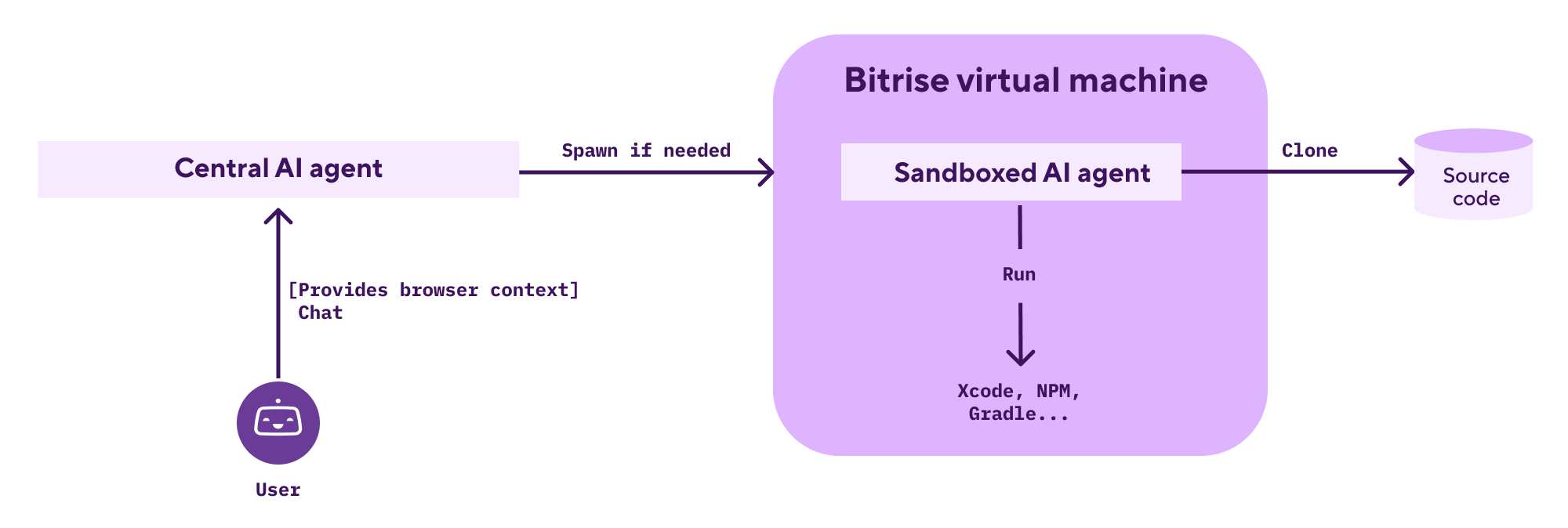
Our platform supports two distinct agent types, each optimized for different use cases.
Sandboxed AI agents (Part 3)
The sandboxed agent runs in a Bitrise virtual machine or container. It interacts with customer code, just like Bitrise builds do. It can access source code, execute developer tools, run tests, and leverage all existing infrastructure improvements.
The trade-off is startup time. Sandbox initialization ranges from a few seconds to a minute depending on cluster load, which may not suit chat-like interfaces where users expect instant responses.
Central AI agent (Part 2)
The central agent runs continuously in our Kubernetes cluster, offering near-instant response times. However, it has limited access to customer data: specifically, it cannot manipulate source code or run commands for testing or building.
This is a typical chat bot, accessing the customer's Bitrise resources and optimizing for Bitrise features. It also fetches context from the user’s browser window and has some tools that let’s it interact with Bitrise webpage’s in the same browser window. It can also spawn sandboxed AI agents when it encounters limitations, giving users the best of both worlds.
Non-functional building blocks
Production AI features need more than just LLM access. We measure and report various metrics at both the LLM proxy and AI agent level, such as:
- Requests per second
- Token usage and costs
- Error rates
- Agent-specific data like tool usage statistics
These metrics are crucial for early issue detection, supporting the monetization of AI features, managing budgets effectively, and offering customers a predictable pricing structure.
The benchmarking challenge
Testing and benchmarking LLM features is notoriously difficult due to their unpredictable nature: 10 runs may yield 10 slightly different results. Mocking often defeats the purpose since we need to measure this variance statistically.
Our E2E testing and benchmarking framework:
- Defines the test suite declaratively
- Bootstraps real-life environments in Docker containers
- Executes the agent
- Asserts results using both programmatic checks and LLM-based judges
This framework runs benchmarks in approximately 10 minutes, enabling fast iteration cycles as we improve our agents.
Our strategy is fully outlined in Part 1 and Part 3. The final steps involved were ensuring we caught regressions before production release and continuously monitoring the AI agent's performance.
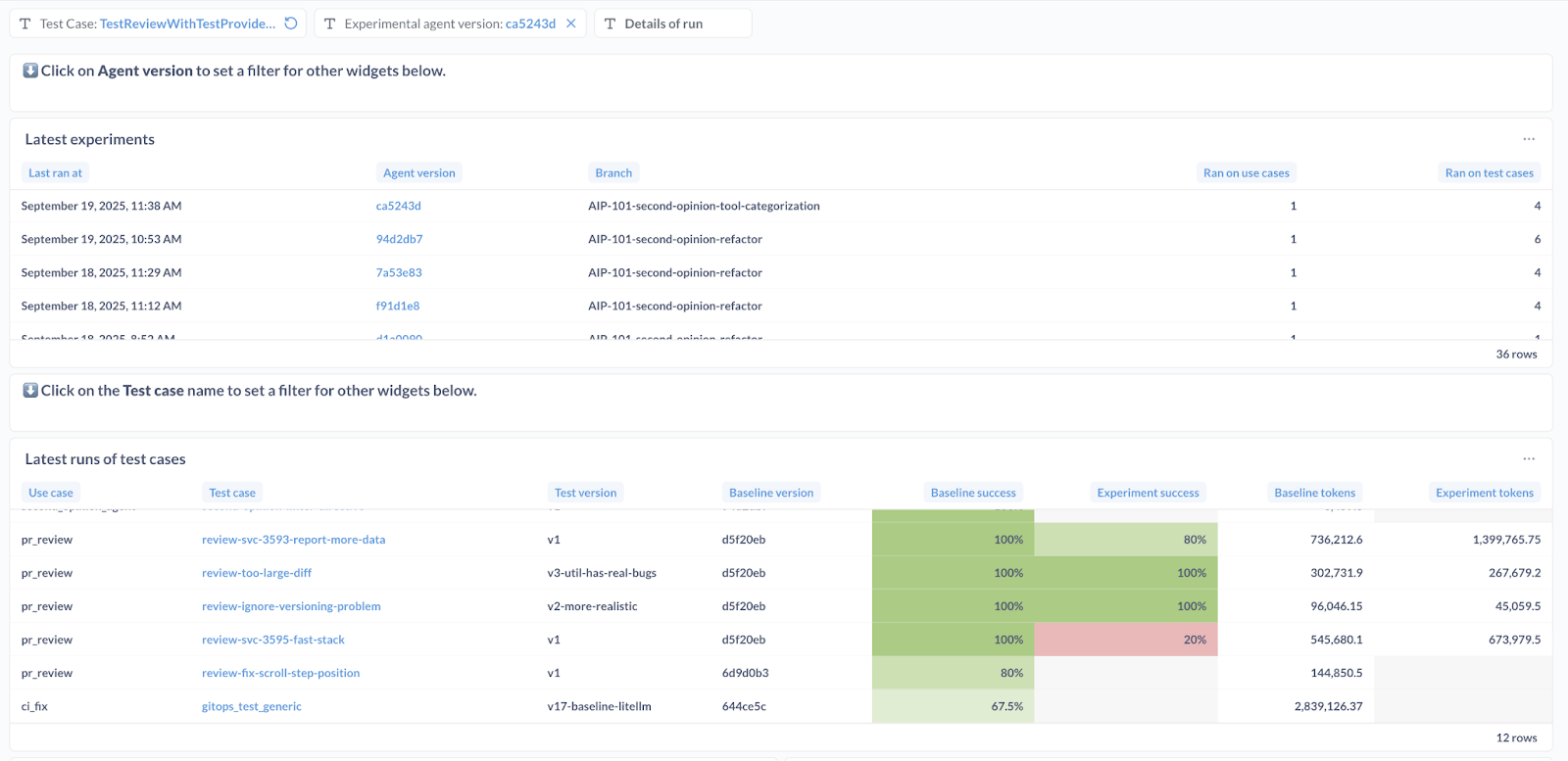
We implemented a lightweight integration with our existing benchmarking stack to enable these features.
- Baseline tracking: every PR merged into the main branch of our AI agent automatically triggers a new benchmarking run, establishing and updating our baseline performance metrics.
- Performance vetting: we run an "experimental" benchmark for each new PR and compare the outcomes against the latest baseline. Significant performance degradation necessitates further iteration on the changes.
Building features on the platform
Customer-facing teams implement AI features using the building blocks detailed above. The process typically involves adding a command, prompts, and tool definitions to an AI agent, plus test cases to the E2E suite.
We have also documented our most valuable lessons, along with helpful tips and tricks, in a collection of "How-to" guides.
Closing thoughts
The foundation we've built—a custom agent framework, a production LLM proxy, comprehensive observability, and a statistical benchmarking suite—positions us to ship AI features faster and more reliably. More importantly, it lets teams across Bitrise focus on solving customer problems rather than reinventing infrastructure.
This concludes our four-part series on AI development at Bitrise. If you're building AI features for your own platform, we hope our journey, from evaluating existing tools to building custom infrastructure, provides useful insights for your own path forward.
Get started for free
Get a 30-day free trial and join the 400,000+ mobile developers who already love Bitrise.
Start free trial

