
Note: This article is the second in this series. 🎉 Check out the first one here: Why we ditched frontier AI agents and built our own.
Improving the Bitrise dev experience with a powerful AI copilot
Almost every product has an AI-based chatbot now. At Bitrise, we wanted to go one better and bring our users something truly useful: a powerful AI assistant that acts as your co-pilot, speeding up tedious tasks and helping you quickly pinpoint bottlenecks and redundancies.
Our AI assistant can handle broad, open-ended questions: for example, you could ask it “How can I help my engineering team build faster?” The assistant knows the Bitrise platform and your account context inside out, and you can also grant it control over your browser tab. With this access, your assistant can quickly identify bottlenecks, navigate to the right page, show you the results, and suggest steps to boost your team’s productivity.
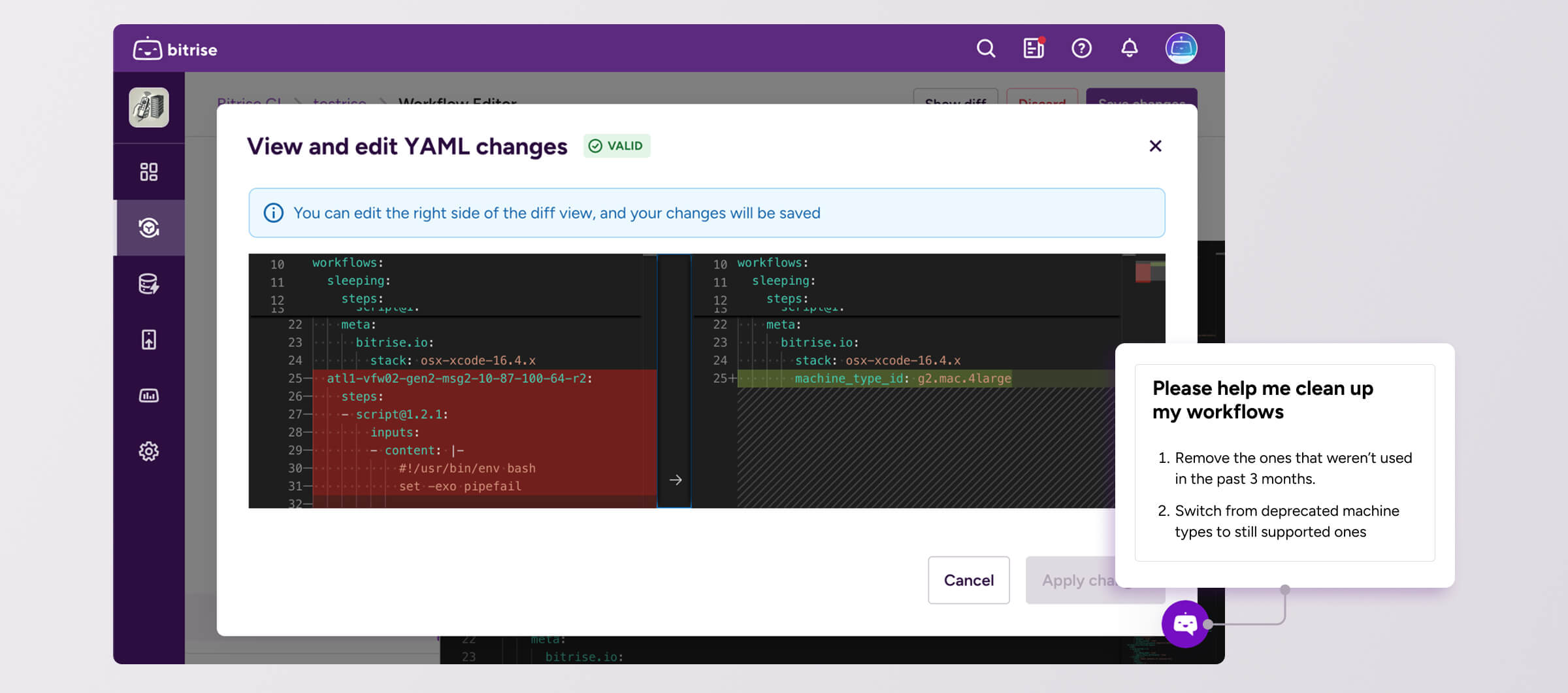
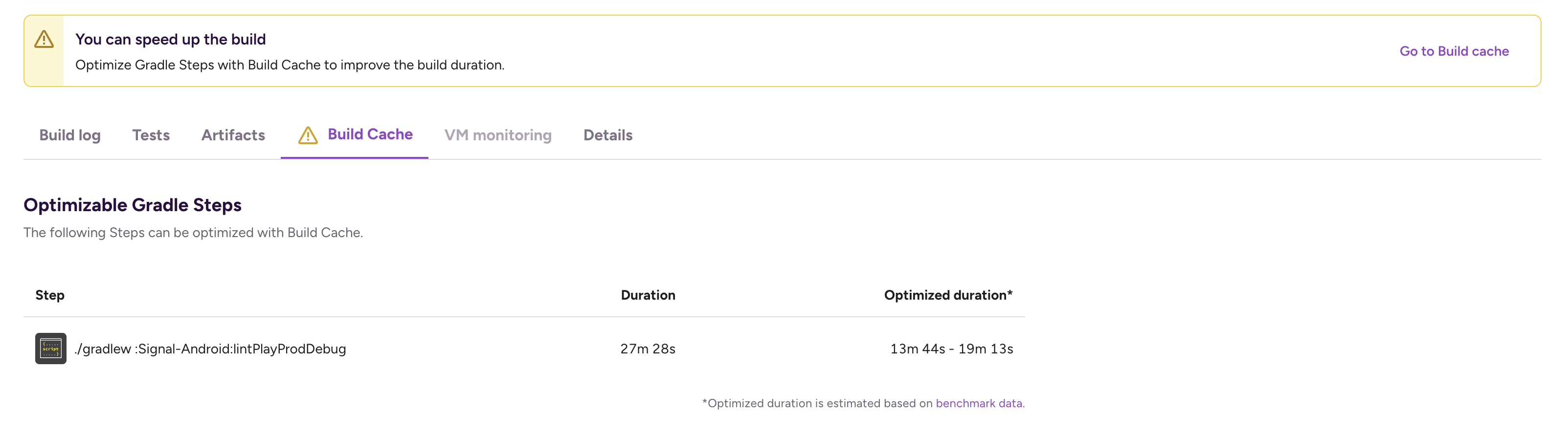
You could also ask it to clean up your Bitrise workflows. In this example, the assistant would navigate to the workflow editor, open the existing diff viewer, and perform the clean-up without saving, and then show its suggested changes so you can discard or apply them.
Exploring possible implementations of this product vision ran parallel to benchmarking AI LLMs and coding agents in early 2025.
How it works: Pydantic.AI proof of concept
The exploration began by searching for frameworks that support building LLM-powered applications. There were many options. Popular ones like LangChain and CrewAI offered numerous features and a strong ecosystem for development and production. However, while their high abstraction level speeds up feature addition, it also slows or blocks debugging and optimization without a rewrite.
Exploring further, we found Pydantic.AI. It seemed to match our needs, allowing model-agnostic agent implementation, lightweight agent and tool definitions, and enforcing type-safe LLM responses. As I will describe in the next section, we ended up using a different framework, but we gained key insights from our experience with Pydantic.AI.
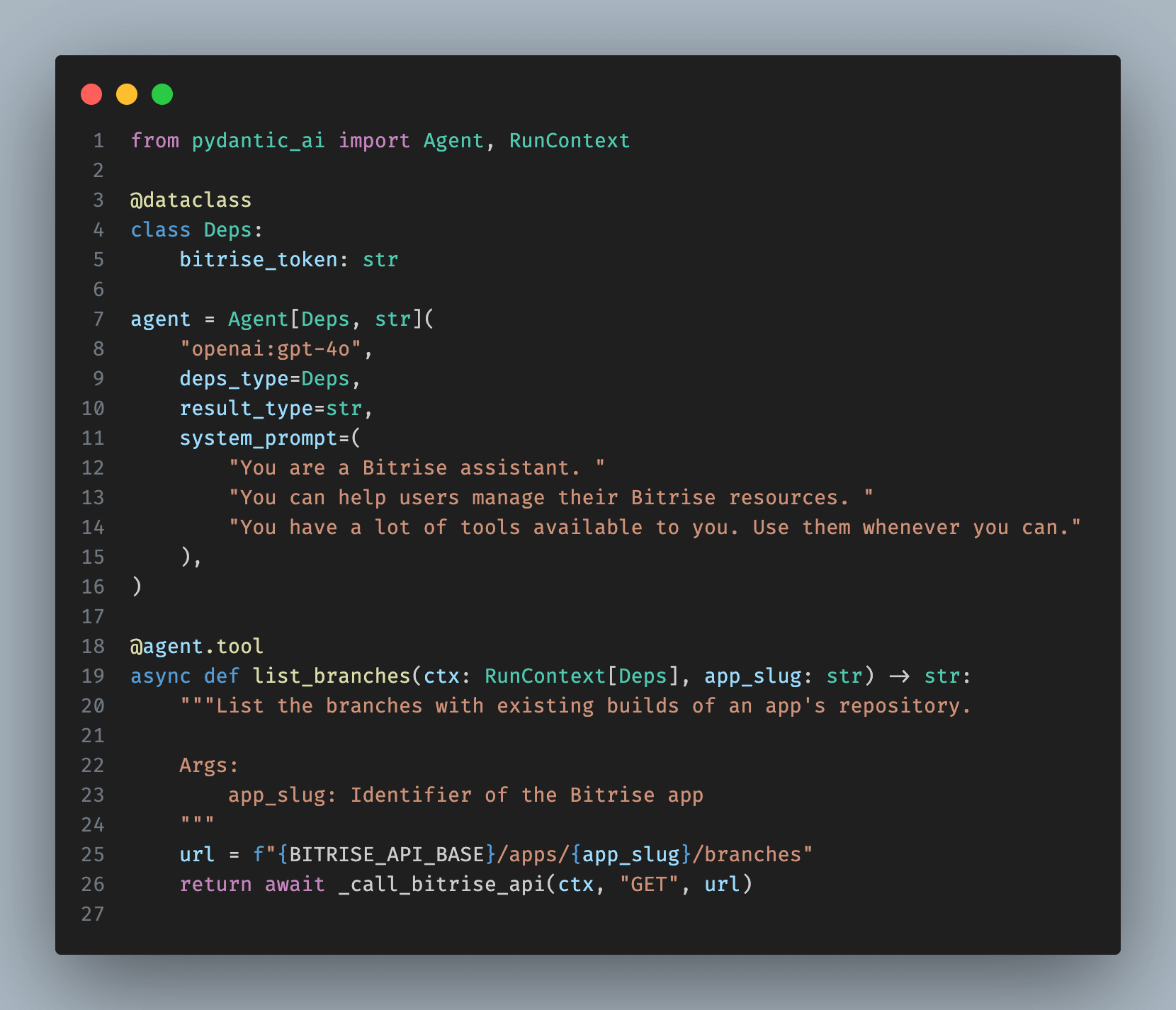
Above is a snippet of the key parts of the AI assistant implementation using Pydantic.AI. We define an agent by specifying the LLM provider, the model, and the system prompt.
Next, we define the dependencies for an agent run. Here, we only need the Bitrise API token of the user interacting with the assistant. These dependencies are passed only to programmatic tool calls, not to the LLM.
We also define the result type of the agent run. In our case, it is a simple free-form string, but we can request a structured result type where the LLM outputs a JSON object. Pydantic.AI validates this format and, if incorrect, prompts the LLM for correction.
The last part in our example defines the list_branches tool. Adding the @agent.tool decorator lets Pydantic.AI automatically convert the function name, parameters, and description into a tool definition expected by the LLM API (see the JSON schema expected by Anthropic as an example).
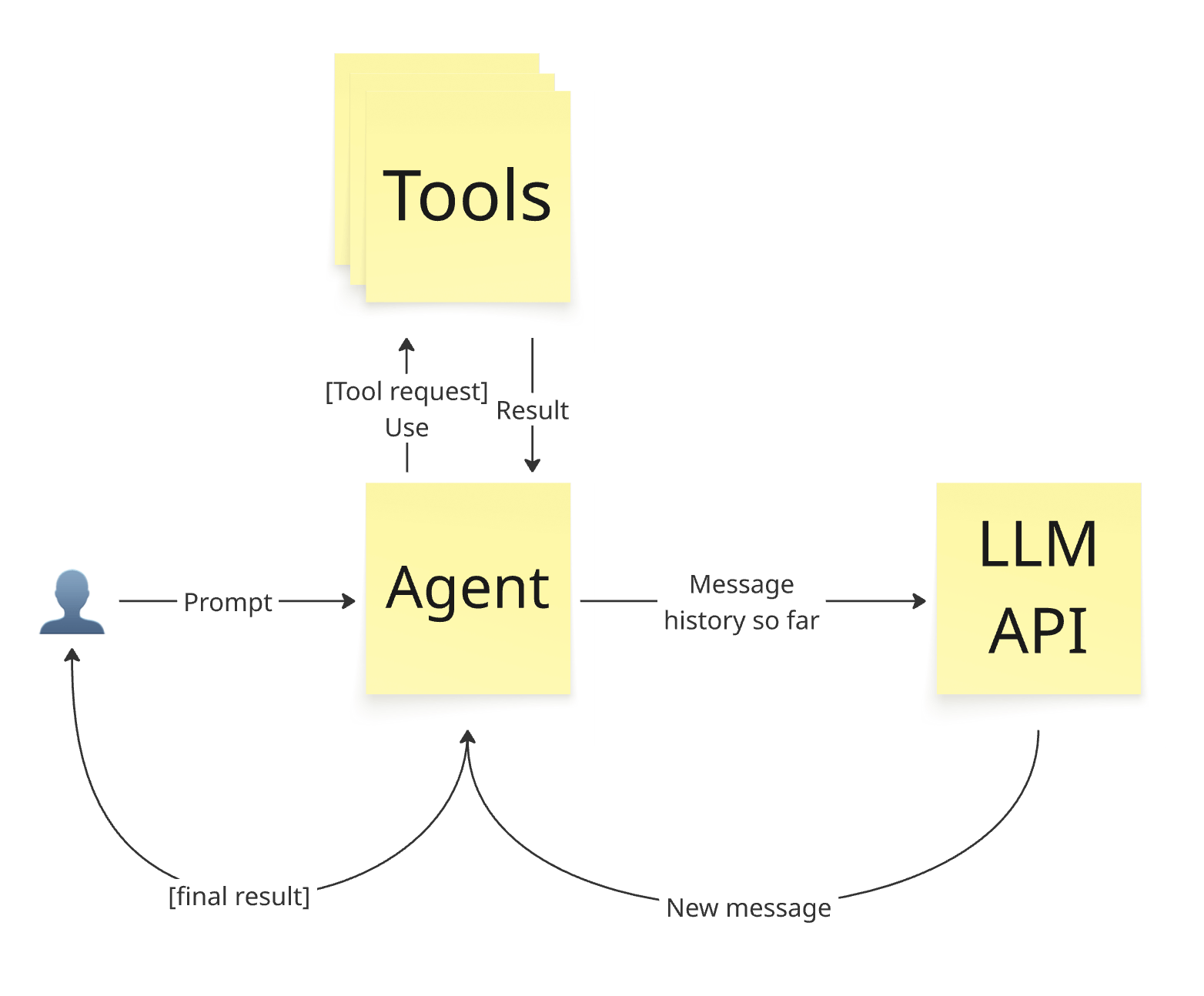
When the agent runs, it sends the system prompt, user prompt, and tool definitions to the chosen LLM API. The API returns either a final result or a tool call request. If it returns a final result, Pydantic.AI sends it to the caller and ends the agent run. If it returns a tool call request, Pydantic.AI calls the corresponding function. In our case, list_branches returns a string result, which converts to a tool response. LLM APIs usually do not store conversation history (recently both OpenAI and Anthropic added optional session usage to store history on the backend).
Therefore, Pydantic.AI sends the system prompt, tool definitions, and the entire conversation so far to the LLM API. The API sees the initial user prompt, then its own tool call request, followed by the response. It then returns the next message, which is either a final result or another tool call request. This loop continues until reaching the final result.
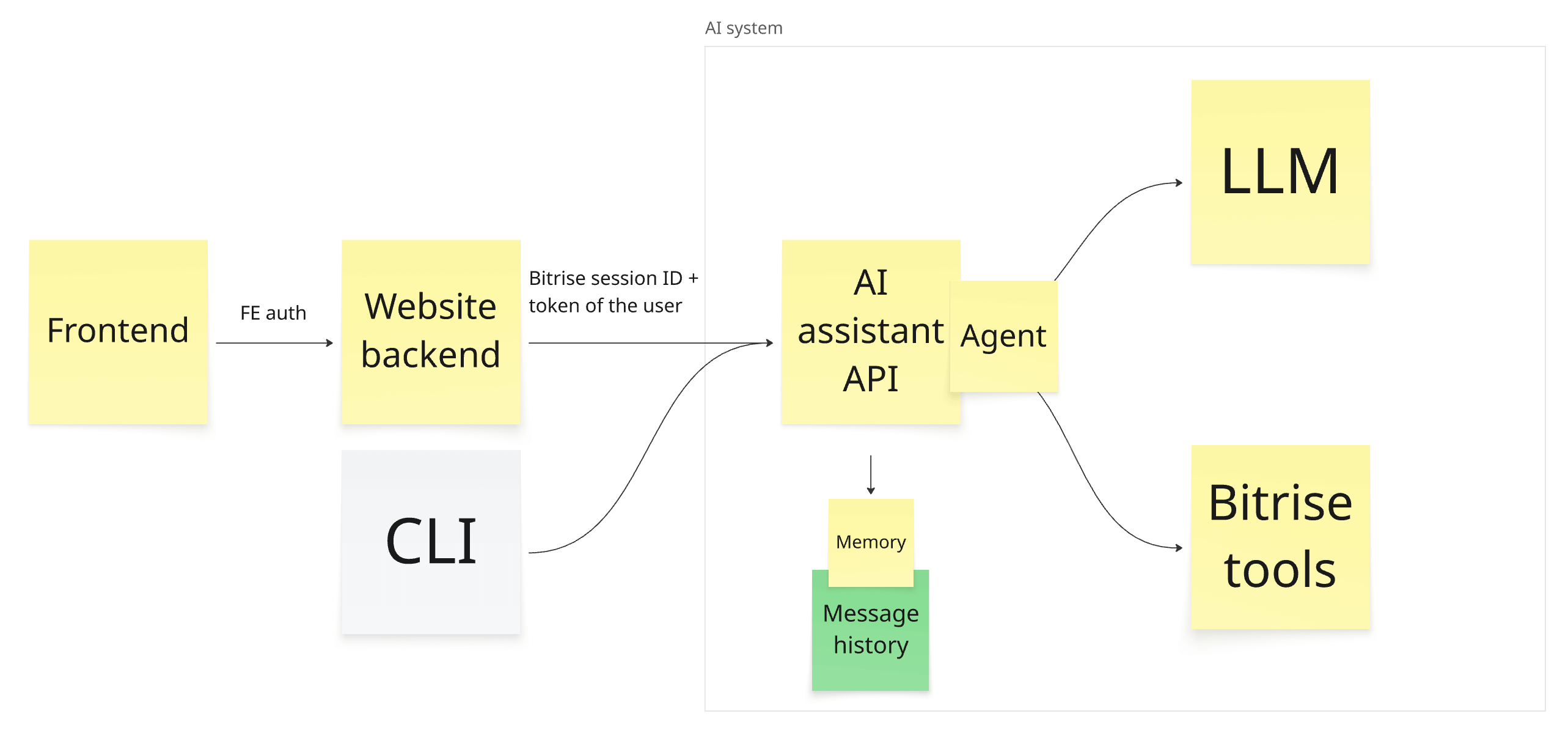
Using this method, we created an AI agent equipped with arbitrary tools. This provides the key building block for our vision; we now need to integrate it into the existing Bitrise ecosystem. The diagram above outlines our initial POC plan. We defined the AI agent and equipped it with Bitrise tools. Initially, we implemented one tool per API endpoint on api.bitrise.io, performing simple HTTP calls.
Next, we wrapped the AI agent in a FastAPI-based (as it looked like the de-facto standard) HTTP API with two endpoints. Clients start a conversation by calling POST /chat, passing the user message and a Bitrise API token. The endpoint forwards these to the AI agent, which may execute operations on the user’s behalf and returns the result along with a generated session ID. Follow-up messages use the session ID in subsequent POST /chat calls. The GET /chat/history/{session_id} endpoint lets clients retrieve the chat history on reconnection.
We implemented a simple CLI client for local testing and integrated the system into the Bitrise website. The frontend sends user messages to the backend service of the UI, using the existing authentication between them. The backend calls our AI API over a private Kubernetes network, proxying the user message, an automatically generated Bitrise API token, and the conversation’s session ID.
We were happy with our progress and found it straightforward to implement features using Pydantic.AI. 🎉
User approval with Pydantic.AI
The next step was requesting approval from the user for tool use on potentially destructive or costly operations. This includes all tools that can modify state; read-only tools are safe to call without explicit human approval. Pydantic.AI now supports Human-in-the-Loop Tool Approval, achieving exactly what we aimed for months ago.
Previously, we had a few other options. The first was to rely on the LLM to handle approvals, returning to the user when a tool use lacked approval. We dismissed this due to the risk of LLM hallucinations during potentially destructive operations.
The second was switching to bidirectional streaming transport like WebSocket, passing the connection as a dependency for tool calls, requesting approval synchronously during the tool call, and blocking execution until receiving a response. We rejected this because it worked around missing core functionality, tightly coupled transport and AI agent layers, and prevented persisting state during pending approvals.
The third was implementing Human-in-the-Loop Tool Approval in Pydantic.AI ourselves. We began but realized our Python proficiency is a lot lower than in Go. We use Go throughout our stack, with standard libraries, developer environments, CI/CD pipelines, and expertise in designing and scaling Go applications for high load and partial outages. Our engineering org doesn’t have this competency in Python, making production readiness costly.
Restart in Go
We searched for a Go library that offered the same qualities as Pydantic.AI, including model-agnostic agent implementation, lightweight agent and tool definitions, and enforcing type-safe LLM responses. No mature option existed then. Initially, we used the official Anthropic Go API Library and implemented the agent loop ourselves to enable state persistence at each step.

The above diagram shows the high-level design of the initial state machine. We enter at “Start” where the user provides a prompt, triggering a transition from the waitPrompt state to the useLLM state. We send the user prompt to the LLM here. One possible response triggers a transition back to the waitPrompt state, sending the response to the user and awaiting the next prompt. The other possible LLM response is a tool use request, triggering a transition to the useTool state. We use the tool immediately if it requires no approval or if it was previously approved, then transition back to the useLLM state. Otherwise, we transition to the waitApproveTool state, requesting user approval. The user either approves, triggering a transition to the useTool state, or disapproves, triggering a transition to the useLLM state.
The algorithm described above matches the agent loop seen previously in Pydantic.AI. The difference is that it now supports tool approvals and explicitly uses a state machine (Pydantic.AI also employs a state machine internally, but we couldn’t hook into it previously).
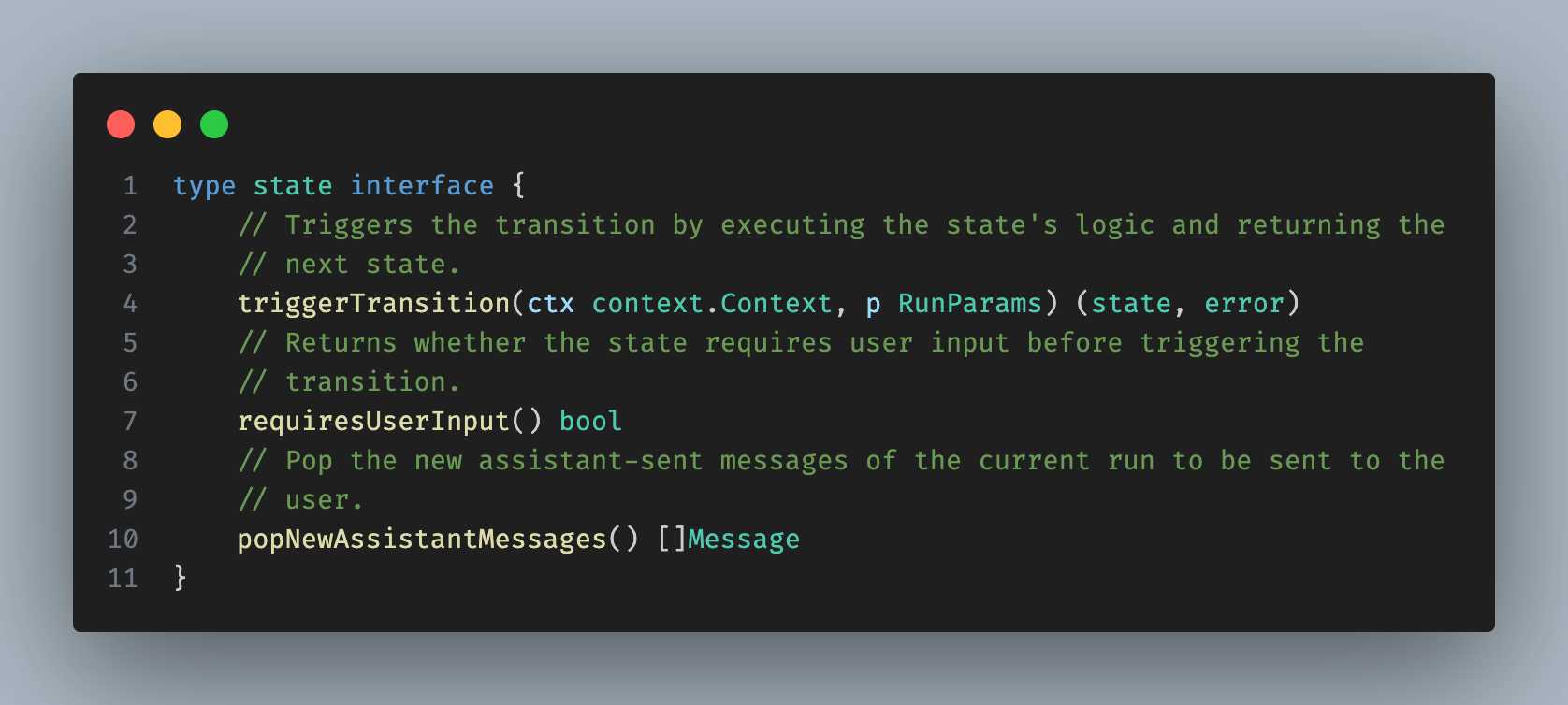
When implementing the agent loop, we will not know the specific states involved in the transition. Instead, we rely on a generic interface implemented by all states. This interface lets us determine whether to request user input or trigger the next state transition immediately.

The agent loop operates as follows: we create a new session or load an existing one, then trigger state transitions until we require additional user input, saving the state after each transition.
This approach supports simple request-response transports like HTTP, returning new assistant messages when user input is needed, loading the state from the session store on the next HTTP request, and resuming from the previous point.
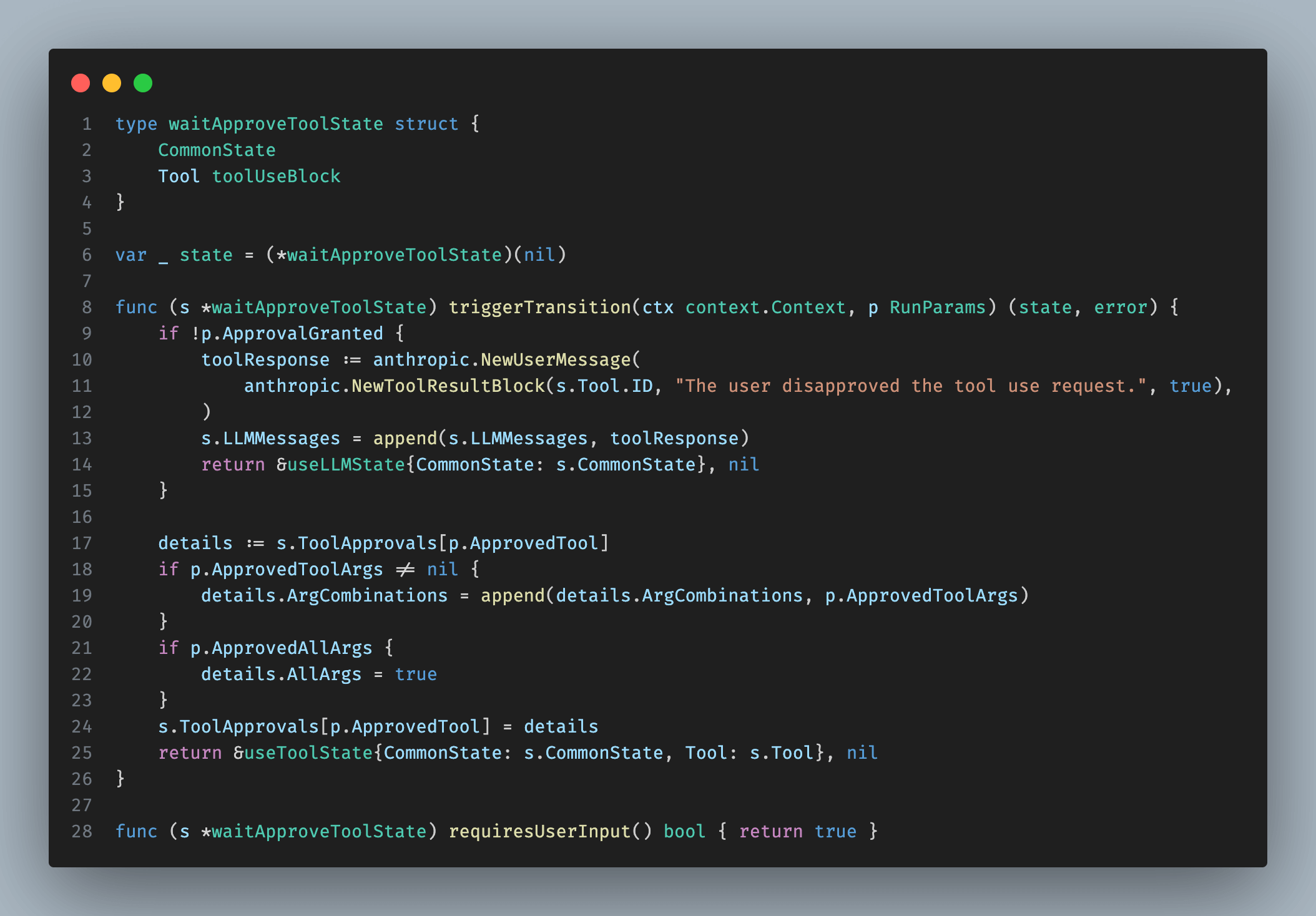
The implementation of the waitApproveToolState state is shown above. We declare that user input is required before triggering a state transition. Once received, the agent loop triggers the transition. If the user approves tool use, we transition to the useToolState, saving the approval details: which tool was approved and with what arguments. These details resemble dependencies in Pydantic.AI; they enable programmatic checks in states and are not passed to the LLM. useToolState can then execute the tool request and return the results to the LLM. If the user disapproves, we append a message to the LLM message history and transition directly to the useLLMState to generate the next step using the LLM.
Hooray, we have a working AI agent again, now in Go, supporting tool approvals and state persistence. 🎉 By writing in Go, a language that gets first-class support in Bitrise engineering, we were able to easily wrap it in our usual Protobuf-generated GRPC and HTTP API, add our observability stack, and complete this milestone, leaving the rest of the architecture untouched.
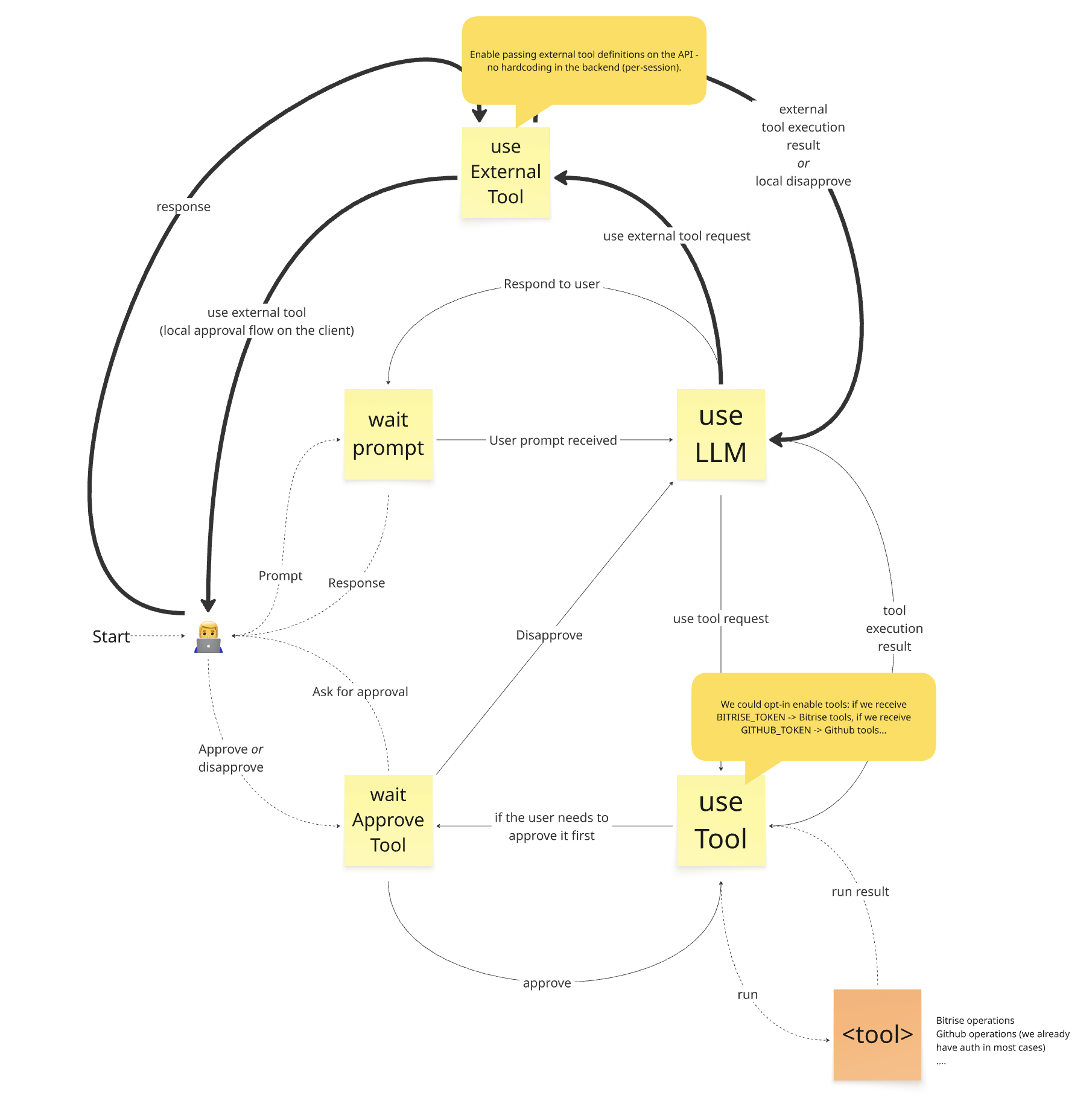
Currently, all tools run server-side, so we can call APIs but cannot control the user’s browser. To enable browser control, we now receive additional client-side tool definitions when the client connects to the API. These are passed to the LLM alongside server-side tool definitions. From the LLM's perspective, all tools are identical; it returns a tool use request as before. We then programmatically decide to use a server-side tool by transitioning to the useTool state or a client-side tool by transitioning to a new useExternalTool state. The latter requires user input, so we return the tool use request to the client to execute the operation in the browser. Once complete, the client returns the result, and we transition to the useLLM state to generate the next step.
We use React on the client side. Tool implementations vary based on the tool's nature and the website section where it operates. For example, a simple navigation tool updates window.location.href, while a Bitrise YML updater tool also updates React states to open the diff viewer modal and propose changes.
This feature was unavailable in Pydantic.AI a few months ago; it is now possible using External Tool Execution.
Conclusion
Thank you for reading. We have completed the final milestone: an AI assistant that acts as your co-pilot by taking control of your browser tab. It turns out that Pydantic.AI now offers everything we were previously looking for, but pivoting to Go was still worth it because we have the competency to confidently push things into production. The next post covers our sandboxed AI agent and its integration with our tech stack. Stay tuned!



