
Context
At Bitrise, our goal is to help developers speed up their builds and automate tedious processes, from first code commit all the way to production release.
To advance this mission, we began exploring how AI can improve developer workflows. Over recent months, I joined a small, fast-moving tiger team focused on cutting through hype to identify valuable AI capabilities. Our goal: to design, develop, and maintain production-grade AI features that truly help developers.
We now confidently build and ship new AI features, detect regressions early, and monitor real-world production performance. This post starts a series sharing our journey, challenges, and lessons learned.
Measuring the performance of AI models and agents
We want to develop features that rely on non-deterministic systems while automatically catching regressions with zero manual effort, keeping iteration speed high.
To evaluate different models and AI coding agents effectively, we needed a way to measure performance at scale, with statistically significant results and low operational overhead to enable fast iteration. Our first step was benchmarking models from multiple LLM providers alongside various AI coding agents. At the start, we found a few open-source solutions that offered similar capabilities (like running tests using Docker containers from a declarative setup) but they often supported only specific environments, such as Python repositories, or relied on predefined agents. None met all our requirements.
Our needs also varied greatly by feature. For example, some use cases involve AI leaving PR review comments, summarizing failed build logs and suggesting fixes, or automatically resolving failing CI builds. Many scenarios require custom setups to enable assertions, such as validating AI-generated PR comments or failure summaries.
We decided to build our own internal eval framework in our preferred language: Go.
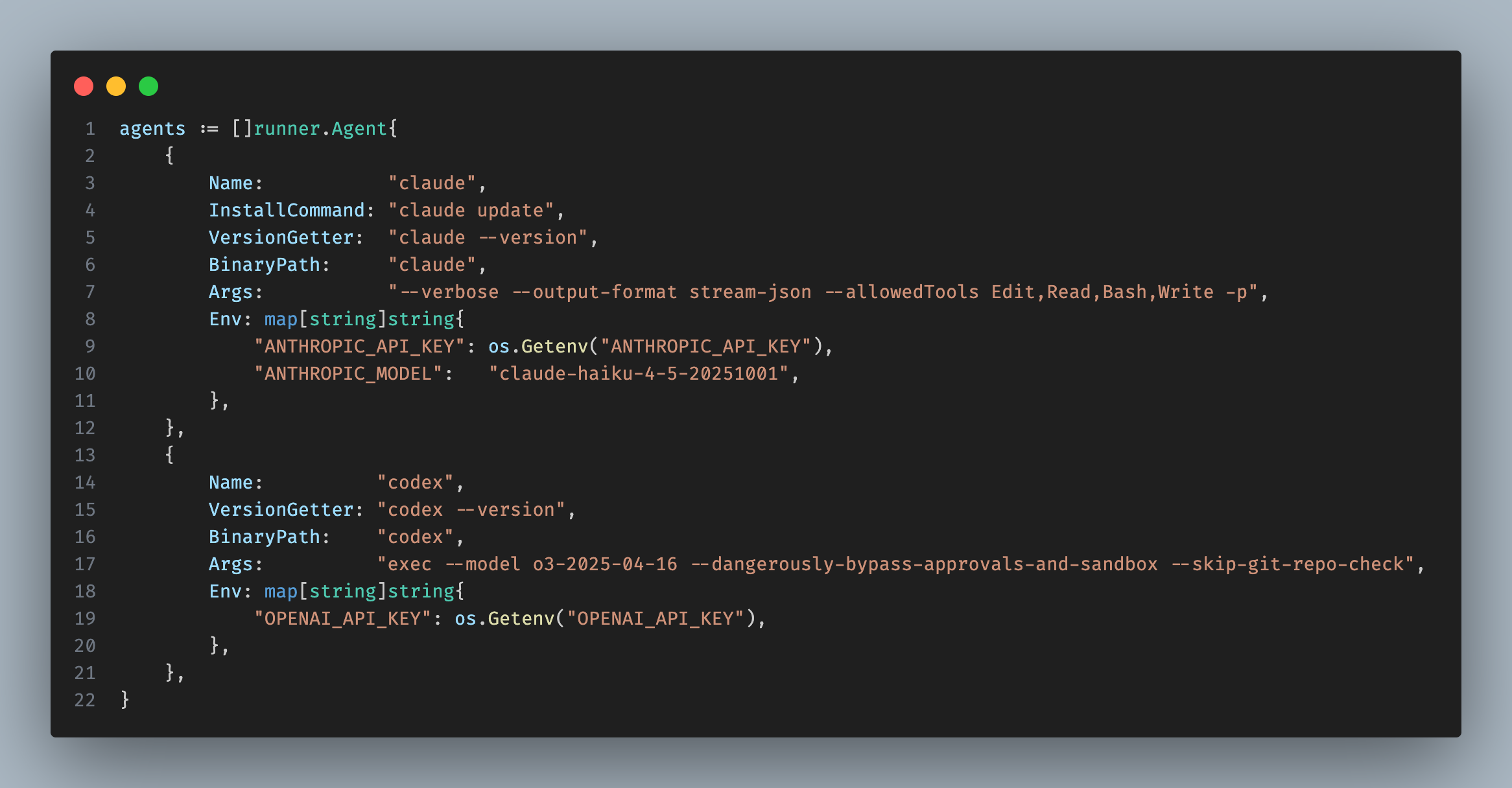
First, we list the benchmarked AI agents declaratively.

Then we define our test cases similarly.
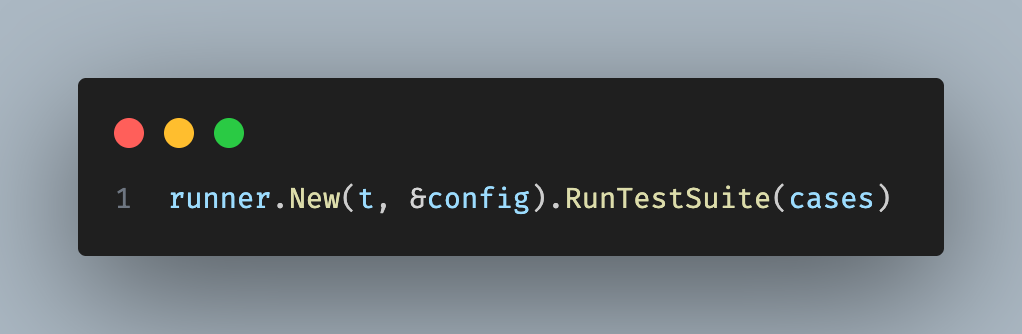
Finally, we pass the agents and test cases to the internal eval framework.

Our goal was to run tests in parallel on all agents and report results to a central database for dashboard viewing.
The framework creates multiple Docker containers, installs the specified AI coding agent, clones the source Git repository, applies patches, installs dependencies, and more. The AI agents run in parallel and usually finish in about ten minutes. We then verify results using programmatic checks (such as running go test ./...) and LLM Judges, who might assess a PR comment from an AI code reviewer. Results go to a central SQL-like database, and a Metabase dashboard displays the latest results.
Alternatives considered
We evaluated several AI coding agents before deciding on our final choice. While many showed promise, only a few stood out as serious contenders.
At Bitrise, we use Claude Code daily. We tested several agents, and Claude Code was our top pick for a long time. It supports Model Context Protocol (MCP) and offers fine-grained permission control per tool. It also stores session data in ~/.claude, making it straightforward to save sessions and restore ephemeral environments. Benchmark results were consistently strong.
However, two drawbacks stood out: Claude Code is closed-source and supports only the Anthropic API. We explored workarounds like using a proxy such as LiteLLM to present an Anthropic-compatible API routing to OpenAI or Gemini on the backend. Still, the closed-source nature posed too much long-term risk for Bitrise, so we expanded our search.
Next, we tried Codex. The OpenAI-powered models responded quickly but struggled to maintain a consistent chain of thought, often veering into unproductive tangents. At the time, Codex was mid-transition from TypeScript to Rust (see GitHub issue #1262). Each implementation was ahead in some respects and behind in others: one supported MCP but lacked sandbox-free runs, while the other had the opposite issue. Ultimately, while Codex improved fast, usability still lagged behind competitors.
We also evaluated Gemini, but testing was difficult. Response times were inconsistent, sometimes taking up to 10 minutes unless resources were explicitly reserved. Google confirmed this was “expected,” and similar complaints appeared in public forums. Since we did not want to reserve resources just for a proof-of-concept, we skipped Gemini for now.
Finally, we examined OpenCode, an open-source coding agent written in Go. It supports all major LLM providers, including self-hosted models, which is a big plus for flexibility. It worked fine with Anthropic APIs but was roughly twice as slow as Claude Code, mainly due to unoptimized prompts and tool descriptions. While it supported non-interactive mode, features were limited because the codebase was tightly coupled to TUI events instead of emitting interface-agnostic signals.
Notable changes since benchmarking
A lot has changed since we first ran our benchmarks. At that time, Sonnet 4 was the latest release from Anthropic. Since then, Sonnet 4.5 arrived. While it did not improve raw performance much, it introduced better context-handling utilities, useful for complex multi-step tasks. Haiku 4.5 also launched, showing results comparable to Sonnet but with significantly lower costs and faster inference times, making it a strong choice for lighter workloads or high-volume automation.
OpenAI released GPT-5 and GPT-5-Codex, with the latter designed for agentic workflows (fewer unnecessary confirmations, more autonomy). We re-ran benchmarks with GPT-5-Codex, and while it showed promise, it still could not outperform Anthropic’s models for our use cases.
On the open-source front, the OpenCode project was archived and its author joined the Charm team to work on a successor called Crush.
Our decision
After exploring all options, we asked a key question: could we build an in-house coding agent matching Claude Code’s performance using Anthropic APIs, but without vendor lock-in?
Turns out, we could.

Building our own agent offers advantages and trade-offs. We can evolve it independently of vendor timelines and avoid breaking interface changes, which was a major issue we encountered with Claude Code during benchmarking. Integration into the Bitrise ecosystem is smoother: we can hook into central logging and store LLM messages in a provider-agnostic format, allowing model switching mid-conversation if needed. We can also design custom system prompts tailored to specific internal use cases.
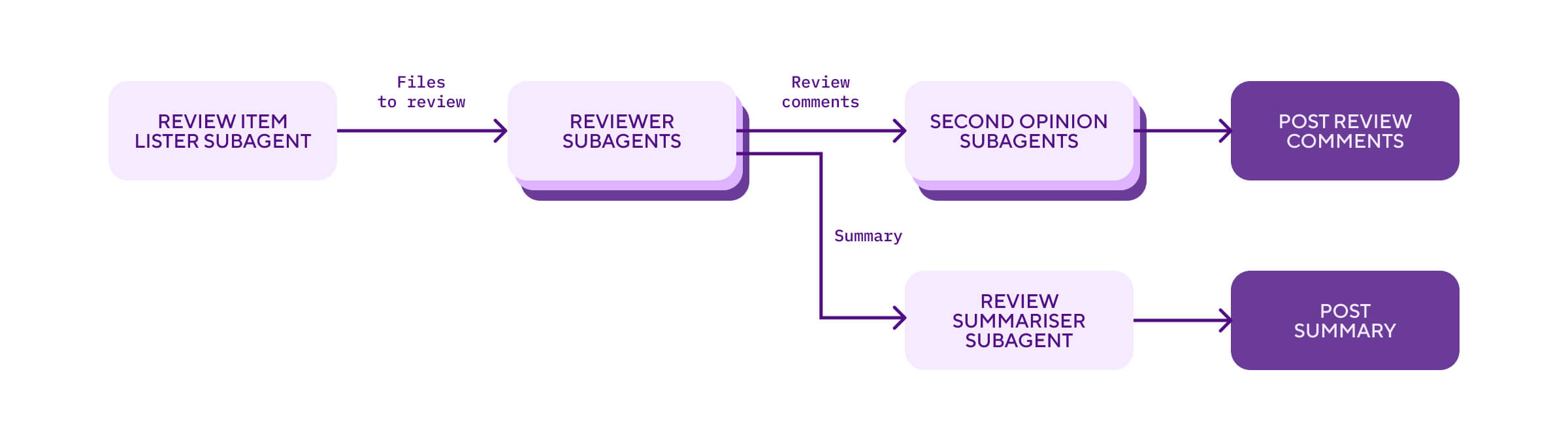
The biggest advantage is programmatic checkpoints. They embed verification and validation directly into the agent workflow, essential for production-grade AI features.
The architecture diagram above illustrates our AI-based PR reviewer system. It uses multiple sub-agents, each dynamically constructed in Go and injected with the right tools and dependencies. These sub-agents run in a coordinated flow, and we programmatically collect and post their results at the end.
We could have built a similar system by spawning multiple Claude Code subprocesses and connecting them via MCP, but keeping everything within the same codebase offers far more flexibility and control.
Writing and maintaining our own agent adds overhead, but the benefits far outweigh the costs. This approach gives us full autonomy, tighter integration, and freedom to innovate at our own pace.
In upcoming posts, we’ll explore the technical details: how we implemented centralized and sandboxed AI coding agents, and how we scaled AI feature development across the company, bringing them safely and efficiently into production.



