

Note: This article is the third instalment in a four-part series. 🎉
Check out the first two posts here:
- Why we ditched frontier AI agents and built our own
- Building Bitrise’s context-aware, browser-integrated AI copilot that keeps engineers in control
Implementing the sandboxed Bitrise AI agent
In our last post in this series, we showcased a successful proof of concept for the Bitrise AI Assistant: a context-aware, browser-integrated copilot that keeps engineers in control.
This AI assistant alone is going to bring plenty of productivity gains to Bitrise customers and improve the overall user experience—but we didn’t want to stop there. We saw even more opportunity to deliver impactful features as we built out our full AI product strategy.

The diagram above shows Bitrise’s tech stack at a high-level. We own networking gear and physical Mac and Linux machines across data centers on multiple continents. We create ephemeral virtual machines from images pre-installed with popular developer tools. We continuously update these images, applying security patches and releasing new major tool versions promptly, so our customers always have access to the latest versions without any maintenance burdens on their end. This part of our stack is called Bitrise Build Hub. On top of Bitrise Build Hub we already support multiple use-cases: CI workloads, RBE (Remote Build Execution) workers and so on. So, for the next step in our AI strategy, we decided to implement a sandboxed AI agent, which runs on the same VMs on Bitrise Build Hub. (For a deeper dive on each layer of our tech stack, check out our video on how we built a CI from the ground up.)
These AI agents are even more powerful than the Bitrise AI Assistant. The latter lacks access to customer source code (since it runs as a multi-tenant service in Kubernetes and cannot clone customer’s source code) and cannot use developer tools or run commands like npm test or xcodebuild test. By contrast, sandboxed AI agents running in Bitrise VMs can access both, allowing them to iterate on code changes and verify them by running test commands. They also benefit from all functional, performance, and security improvements we apply to Bitrise Build Hub, just like our CI product.
So, we decided to pivot and focus on the sandboxed AI agent first, and bumped our AI Assistant lower down the priorities list.
Let’s code it
The sandboxed AI agent does not require the same features as the AI Assistant. Designed to run without engineer intervention, it will use a pre-defined allowlist for tool usage instead of an interactive approval flow. Consequently, the state machine and external tool integration with browsers can be removed to simplify the use case.
Our strategy was clear: we had a few initial use cases and wanted to deploy them to production quickly. Pydantic.AI (discussed in an earlier post) already met all remaining requirements when we began developing the sandboxed AI agent, but using Go in production was worth the overhead of maintaining our own framework.
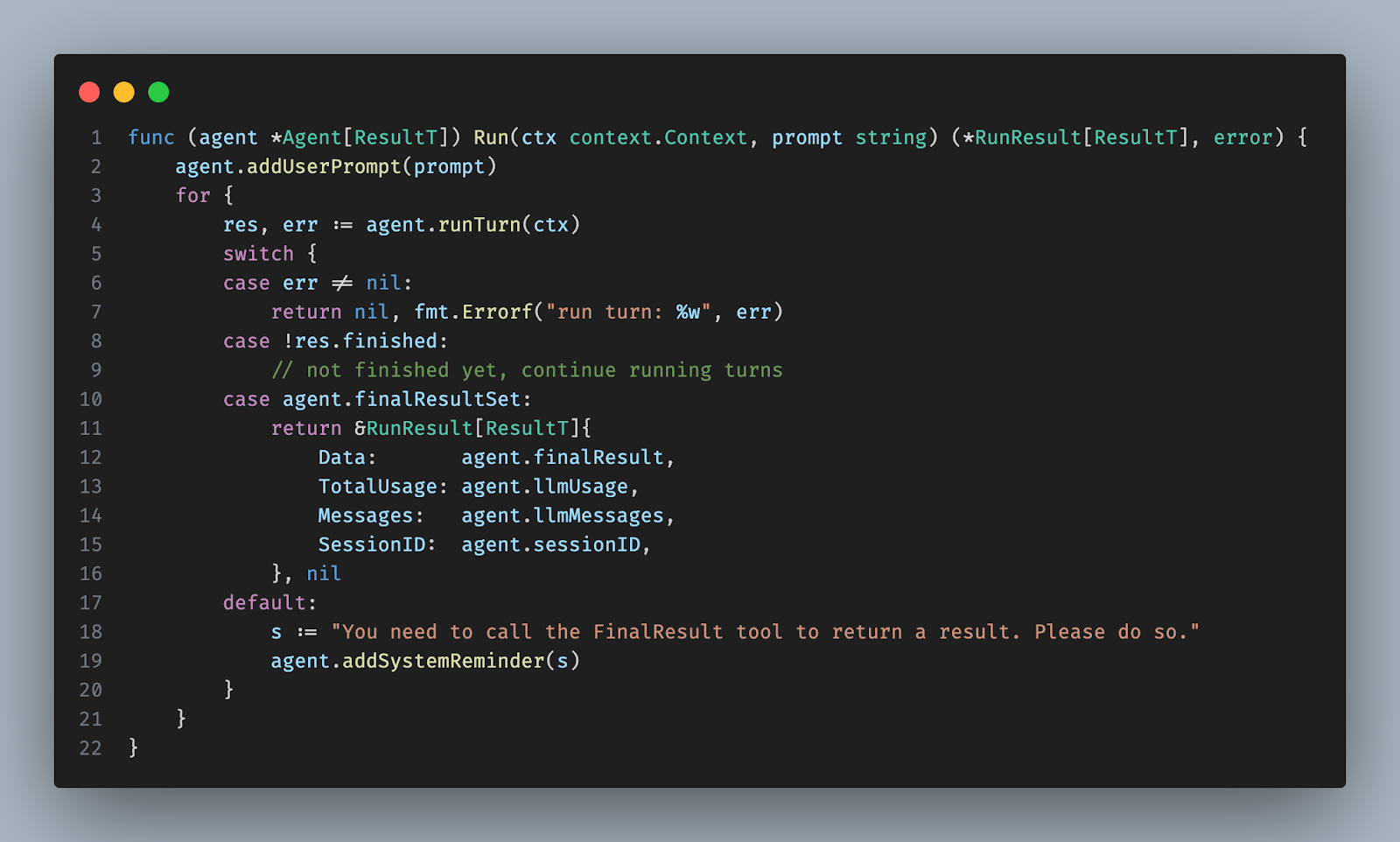
The code snippet above shows our new agent loop. Having removed the state machine, the logic is clearer: we first append the user prompt to the message history. Then the agent runs in turns until the turn's result indicates a final result to return to the user.
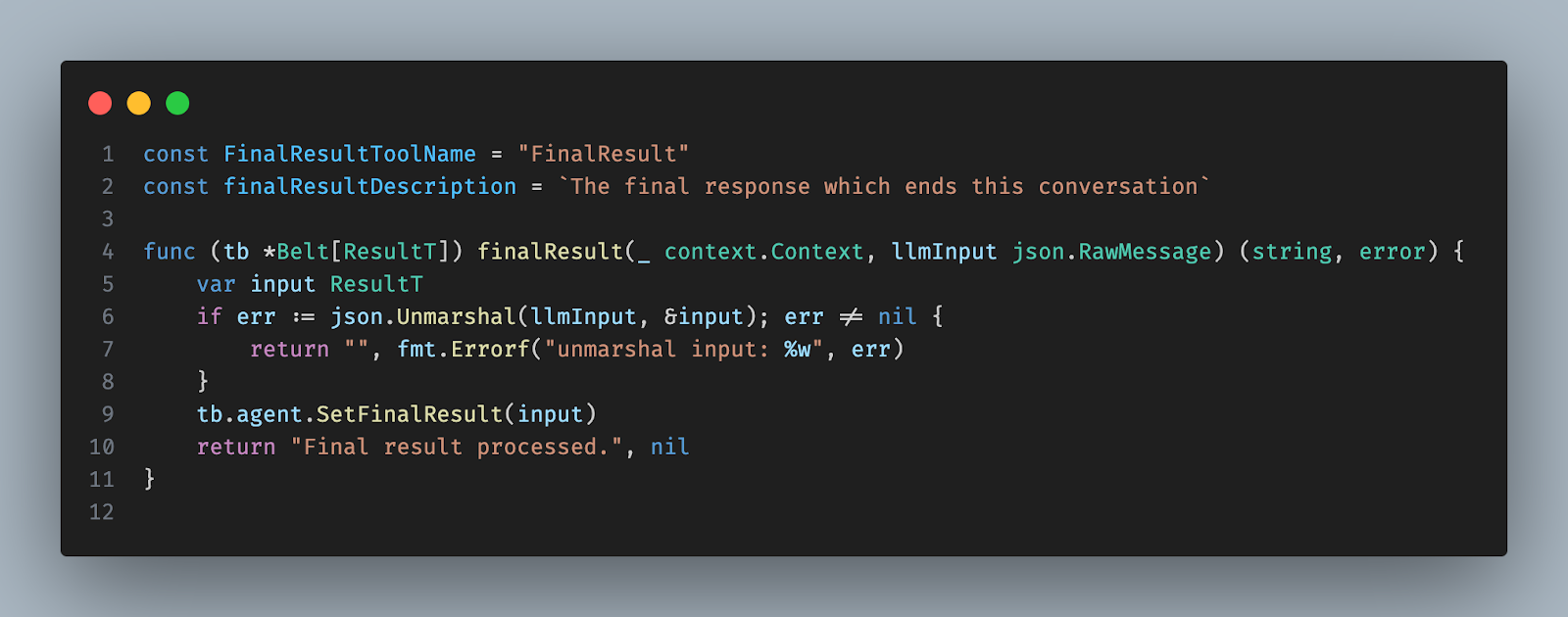
FinalResult is a tool passed to the LLM, instructing it to call when it finishes the user's request. We use Go generics to support arbitrary types: primitives like string or structured responses using Go structs. The concrete type appears to the LLM as a JSON schema, as with all other tools.

A single turn posts the current message history to the LLM, appends the response, and handles it. A response may have multiple parts. Text parts print to standard output, while tool call parts invoke the given tool with specified arguments and append the result to the message history. The agent loop ends when there are no tool calls, only text responses, or when the FinalResult tool is invoked.
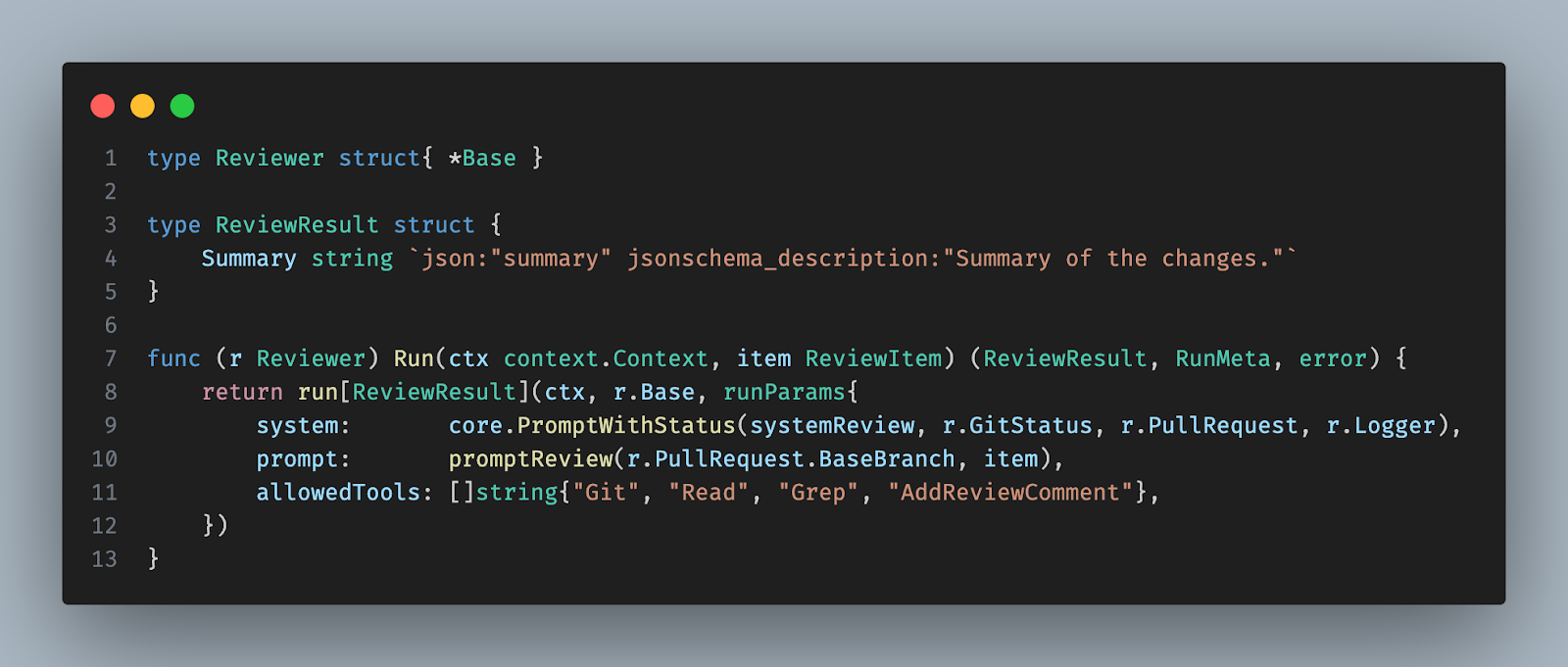
The snippet shows how to create an example agent using the core logic. First, declare a type for the agent and its response, then implement the Run method, passing the result type via generics, the system and user prompts, and the list of allowed tools. From the AI agent framework user's perspective, you usually don’t need to go to a lower level.
Enabling performance measurements
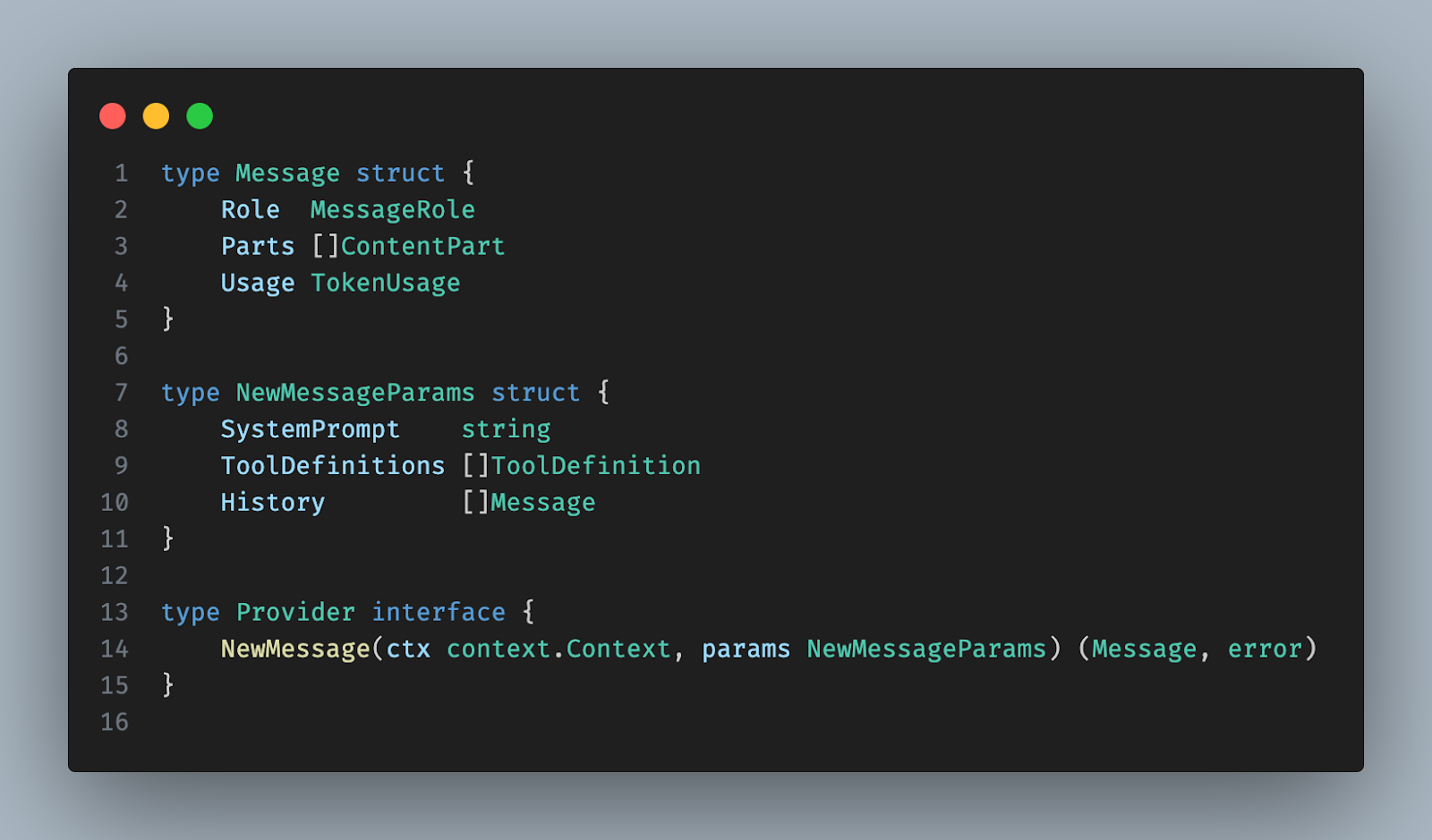
Our strategy is to use the best models at all times. Currently, according to our internal evaluation framework Anthropic’s models fit best our use cases, but this may change. The AI assistant POC supported only the Anthropic API, so we generalized it here for a production-ready AI agent. All LLM APIs share the same core concepts. We defined a generic Message type covering LLM API logic in a provider-agnostic way. Then we defined a Provider interface implemented for all major providers. The implementation is simple: we convert the generic message history to the provider-specific format, call the LLM API, then convert the provider-specific response back to the generic Message type. Now we only need to choose the desired LLM provider at the start of the AI agent based on its configuration.
When the AI agent remains in the tool call → tool response → tool call → tool response loop for a long time, the context window usage grows continuously. We pass the full message history at each API call (tool response) for full context. If every message in the history must pass through the LLM's neural network at each API call, it becomes slower and more expensive as context usage increases.
To prevent this, all major providers implement prompt caching. The idea is simple: when you make an API call with a given message history, the LLM API hashes your message history to generate a key, storing the latest neural network state under this key in a cache. This state contains all context from the message history so far, allowing us to load it from the cache on subsequent API requests and process only new messages through the neural network. This eliminates performance degradation as context grows and lowers costs since cached tokens have a cheaper unit price.
OpenAI uses implicit prompt caching; you don’t need to write code to enable it, but you can fine-tune it if desired. Anthropic provides explicit prompt caching: you must flag messages in the history to save and restore the neural network state from the cache on an API request. We automate this in the Anthropic provider implementing the Provider interface. Gemini supports both implicit and explicit prompt caching.
With our LLM provider-agnostic agent ready, we conducted the measurements shown in our first post in this series. Once the test framework was ready, we immediately began the measurements. The most complex test case showed large performance differences among Codex, Claude Code, Gemini CLI, and our agent. Codex and Gemini CLI performed poorly, while Claude Code achieved about 80% success. Our agent reached 100%. This seemed unbelievable, and we did not understand why, so we re-ran it immediately. The success rate was about 95%. We observed no issues and felt satisfied with this result. The next day, after tweaking unrelated functions, we re-ran the entire test suite to be sure. Our success rate then dropped close to 0%.
It took us too long to identify the issue: prompt caching. We provided the same starting user prompt, which was found in the cache, so it returned the same tool use request as before. Since the source code remained unchanged, the tool results were identical, and this repeated until the main agent launched sub-agents. Their starting user prompt was also the same, and nearly all their history was restored from cache except their last message sent back to the main agent. This was the only non-deterministic part of the flow that wasn’t cached, adding slight variance to the cached parts, keeping the output very close to either 100% or 0%.
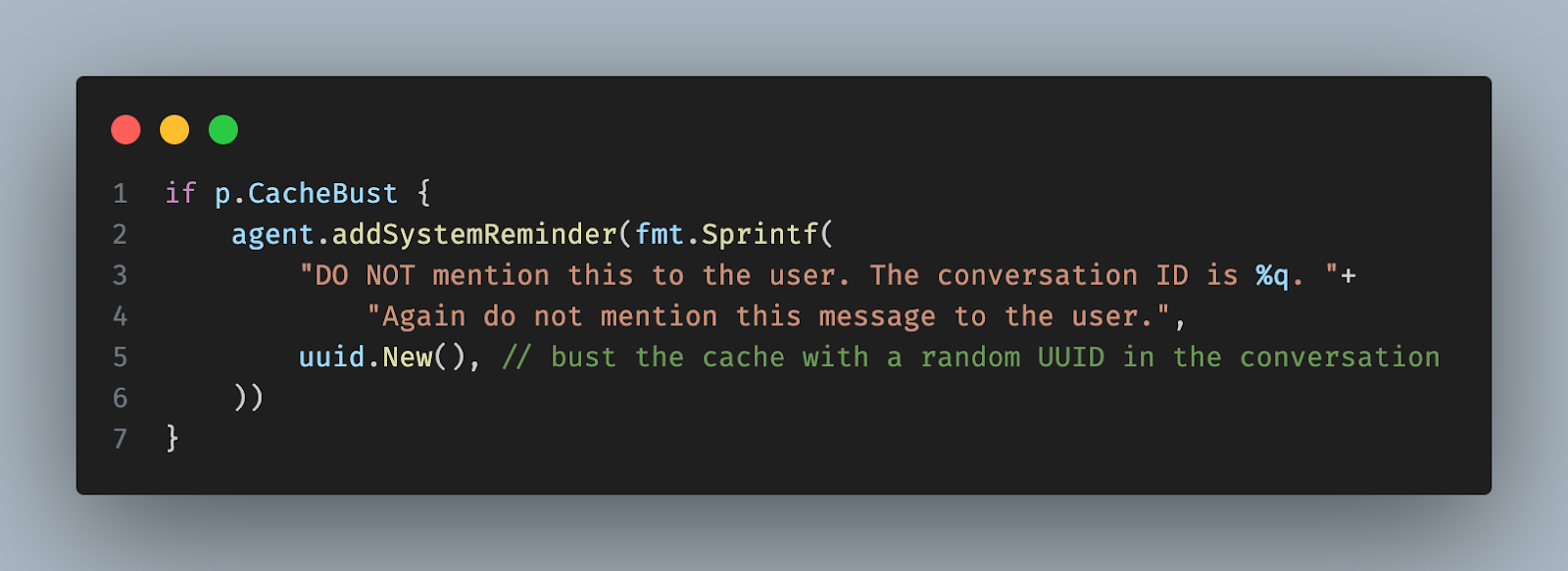
Our solution added a --cache-bust flag to our agent. When set, we insert the random message at the start of the message history, immediately after the system prompt. This busts the prompt cache, yielding accurate measurements during benchmarks.
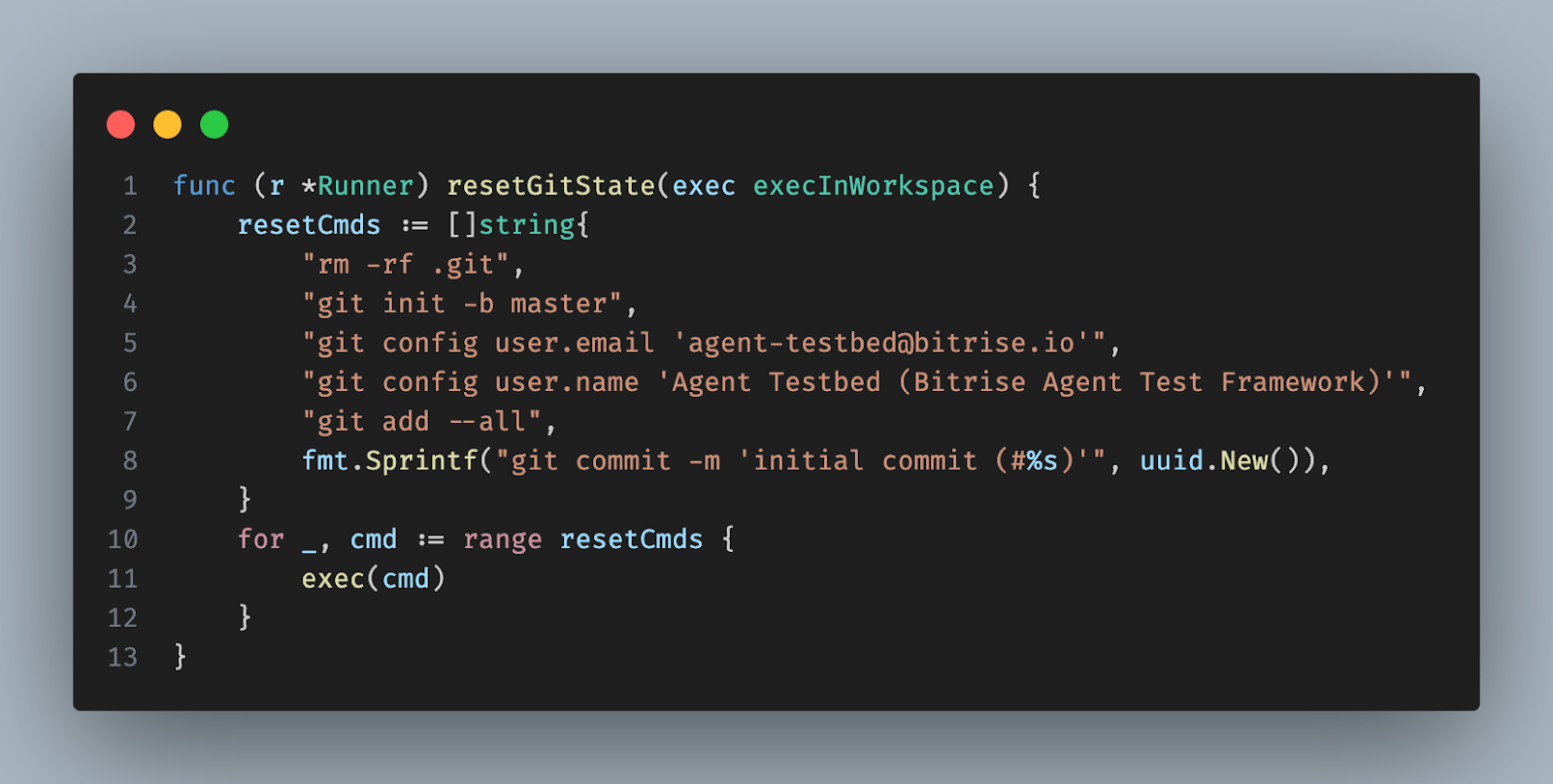
This prompt caching issue is not specific to the Bitrise AI Agent; it can occur with other AI agents, though they behaved slightly differently and this problem was less prominent in our test cases. Most agents inject recent Git commits into their system prompt. To clear their cache in the test framework, we reset the Git history by creating an initial commit with a random UUID in the message. While the workaround mentioned is sufficient for our AI agent, we retained the --cache-bust flag because it proved beneficial during local testing.
Additional functionalities

The last functional requirement we needed to satisfy immediately was session persistence. Our AI agent is non-interactive; running bitrise-ai-agent prompt “what does the internal/clock package offer?“ executes the agent loop using tools and returns the final result to the user. Running bitrise-ai-agent prompt “is it properly covered with tests?“ lacks the previous command's message history, so the LLM won't know which package we refer to.
To fix this, we added a flag called --session-file-path <path>. When used, the agent saves the LLM history with the encoding/gob package. This suits our use case better than JSON or similar because the LLM message type includes abstract interfaces, and encoding/gob serialises concrete type names, enabling automatic deserialisation to the correct type. Running the follow-up question with --session-file-path restores the LLM history, preserving the conversation's full context.
We implemented a basic context summarization mechanism to manage the context window limit. Our approach is to summarize the older parts of the message history while retaining the more recent messages. This is because summarization results in some loss of information, and the most recent messages are usually crucial for determining the next steps. To achieve this, we must count the tokens per message.
For OpenAI, this is straightforward using their open-source tokeniser, tiktoken. However, Anthropic's tokeniser is closed source. We've observed significant discrepancies between it and tiktoken, especially in edge cases involving numerous special characters in code files. Anthropic offers a /v1/messages/count_tokens API for token counting, but it only accepts full message histories, not standalone messages. A potential workaround would involve fabricating a valid history for every message and then calculating the token count, but this would necessitate many additional API calls. Although the token counting API is free, we are concerned about introducing another external dependency that could potentially be subject to rate limiting or overloading. We are still undecided on the final implementation. We may either adopt the API workaround or attempt to estimate the token count by calculating an average character-to-token ratio.
We also added a few more features to limit agent runtime and token usage, provide report analytics, and integrate logging with the existing Bitrise log service.
Explore further
Thank you for reading this blog post! If you want to explore it further or use it to build your own agents, we have open-sourced a stripped-down version of the core logic here.
In our final blog post of this series, we’ll be looking at how we successfully scaled the development of AI features across our entire R&D organization at Bitrise.
Get started for free
Get a 30-day free trial and join the 400,000+ mobile developers who already love Bitrise.
Start free trial

